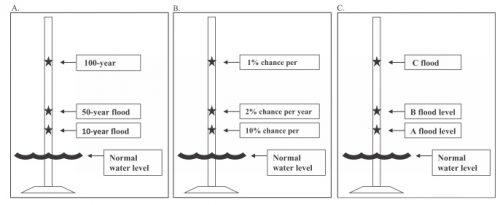
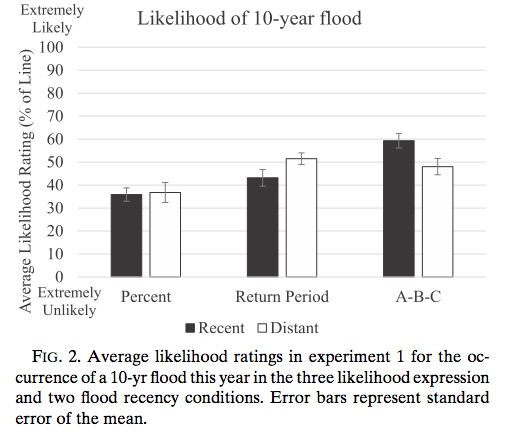
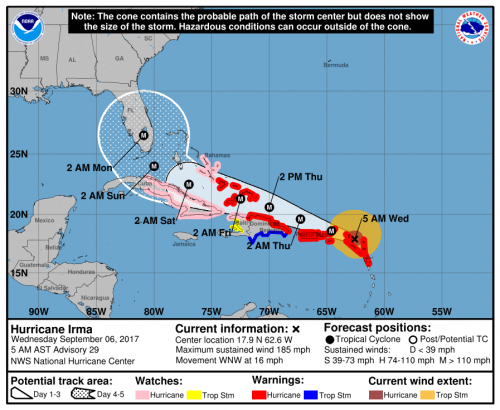
Ready to do it all over again? Fresh on the heels of a $100+ billion hurricane, we very well may be headed for another soon.
As Houston and the Gulf Coast begin a long recovery from Hurricane Harvey, Hurricane Irma is now rampaging through the Atlantic. With 185 m.p.h. sustained winds on Tuesday, Irma became the strongest hurricane in Atlantic history outside of the Caribbean and Gulf. The hurricane made its first landfall early Wednesday in Barbuda and still threatens the Virgin Islands, Puerto Rico, Cuba, and the United States.
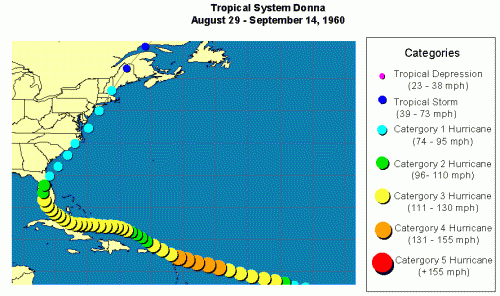
If Irma continues along the general path of 1960’s Hurricane Donna, it could easily tally $50 billion in damage. This estimate, from a study by Karen Clark and Co. (discussed recently on Category 6 Blog), is already four years old (i.e., too low). Increased building costs—which the report notes rise “much faster” than inflation–and continued development could drive recovery costs even higher.
In short, as bad as Houston is suffering, there are do-overs on the horizon—a magnitude of repeated damage costs unthinkable not long ago, before Katrina ($160 million) and Sandy ($70 million).
Repeated megadisasters yield lessons, some of them specific to locale and circumstances. In Miami after Hurricane Andrew, the focus was on building codes as well as the variability of the winds within the storms. After Hurricane Rita, the focus was on improving policies on evacuation. After Hurricane Katrina, while the emergency management community reevaluated its response, the weather community took stock of the whole warnings process. It was frustrating to see that, even with good forecasts, more than a thousand people lost their lives. How could observations and models improve? How could the message be clarified?
Ten years after Katrina, the 2016 AMS Annual Meeting in New Orleans convened a symposium on the lessons of that storm and of the more recent Hurricane Sandy (2012). A number of experts weighed in on progress since 2005. It was clear that challenges remained. Shuyi Chen of the University of Miami, for example, highlighted the need for forecasts of the impacts of weather, not just of the weather itself. She urged the community to base those impacts forecasts on model-produced quantitative uncertainty estimates. She also noted the need for observations to initialize and check models that predict storm surge, which in turn feeds applications for coastal and emergency managers and planners. She noted that such efforts must expand beyond typical meteorological time horizons, incorporating sea level rise and other changes due to climate change.
These life-saving measures are part accomplished and part underway—the sign of a vigorous science enterprise. Weather forecasters continue to hone their craft with so many do-overs. Some mistakes recur. As NOAA social scientist Vankita Brown told the AMS audience about warnings messages at the 2016 Katrina symposium, “Consistency was a problem; not everyone was on the same page.” Katrina presented a classic problem where the intensity of the storm, as measured in the oft-communicated Saffir-Simpson rating, was not the key to catastrophe in New Orleans. Mentioning categories can actually create confusion. And again, in Hurricane Harvey this was part of the problem with conveying the threat of the rainfall, not just the wind or storm surge. Communications expert Gina Eosco noted that talk about Harvey being “downgraded” after landfall drowned out the critical message about floods.
Hurricane Harvey poses lessons that are more fundamental than the warnings process itself and are eerily reminiscent of the Hurricane Katrina experience: There’s the state of coastal wetlands, of infrastructure; of community resilience before emergency help can arrive. Houston, like New Orleans before it, will be considering development practices, concentrations of vulnerable populations, and more. There are no quick fixes.
In short, as AMS Associate Executive Director William Hooke observes, both storms challenge us to meet the same basic requirement:
The lessons of Houston are no different from the lessons of New Orleans. As a nation, we have to give priority to putting Houston and Houstonians, and others, extending from Corpus Christi to Beaumont and Port Arthur, back on their feet. We can’t afford to rebuild just as before. We have to rebuild better.
All of these challenges, simple or complex, stem from an underlying issue that the Weather Channel’s Bryan Norcross emphatically delineated when evaluating the Katrina experience back in 2007 at an AMS Annual Meeting in San Antonio:
This is the bottom line, and I think all of us in this business should think about this: The distance between the National Hurricane Center’s understanding of what’s going to happen in a given community and the general public’s is bigger than ever. What happens every time we have a hurricane—every time–is most people are surprised by what happens. Anybody who’s been through this knows that. People in New Orleans were surprised [by Katrina], people in Miami were surprised by Wilma, people [in Texas] were surprised by Rita, and every one of these storms; but the National Hurricane Center is very rarely surprised. They envision what will happen and indeed something very close to that happens. But when that message gets from their minds to the people’s brains at home, there is a disconnect and that disconnect is increasing. It’s not getting less.
Solve that, and facing the next hurricane, and the next, will get a little easier. The challenge is the same every time, and it is, to a great extent, ours. As Norcross pointed out, “If the public is confused, it’s not their fault.”
Hurricanes Harvey and Katrina caused catastrophic floods for different reasons. Ten years from now we may gather as a weather community and enumerate unique lessons of Harvey’s incredible deluge of rain. But the bottom line will be a common challenge: In Hurricane Harvey, like Katrina, a city’s–indeed, a nation’s–entire way of dealing with the inevitable was exposed. Both New Orleans and Houston were disasters waiting to happen, and neither predicament was a secret.
Meteorologists are constantly getting do-overs, like Irma. Sooner or later, Houston will get one, too.